Automating Incident Response for Exposed AWS Credentials with AWS Health
Introduction
When organizations first begin their cloud journey, particularly small or lean teams, simplicity often takes priority over security best practices. Instead of adopting AWS IAM roles with temporary, automatically rotated credentials, these teams may create shared IAM users with long-lived access keys. This pattern is especially common in environments where data scientists or researchers need quick access for experiments, Jupyter notebooks or batch pipelines. Sharing permanent credentials among several individuals or embedding them in scripts and APIs can feel like the fastest way to get work done without having to manage role assumptions or federated identities.
However, while this approach may reduce initial complexity, it introduces significant risks. Long-term credentials lack the built-in protections of short-lived session tokens, are more likely to be hard-coded into source code or configuration files and add the overhead of having to rotate them periodically. In collaborative teams, the risk is amplified because the same set of keys for a shared user may be passed around informally, leaving little accountability for individual actions. This shortcut for agility can quickly become a major vulnerability if those credentials are accidentally committed to a public repository or shared outside the team. That practice introduces significant risk - once a key is leaked, an attacker could potentially access sensitive data or perform destructive actions across your environment.
In such cases, the speed and reliability of your incident response matters. Detecting an exposed key quickly and collecting forensic evidence can prevent a major security incident. That’s where AWS Health comes in. AWS Health provides proactive notifications about events that could impact your environment, including the AWS_RISK_CREDENTIALS_EXPOSED event type, which is raised when AWS detects that one of your access keys has been publicly exposed.
Proactive Security Awareness with AWS Health
AWS Health is built into your AWS accounts with no additional setup required. It continuously monitors for service issues that might affect your workloads. Health delivers three categories of events. Public events are service-wide notifications, such as information about planned AWS maintenance or regional service issues. Account-specific events apply to resources in your account, such as retirement of an EC2 instance that one of your environments is currently using or IAM credential exposure of a user in your account. Within your AWS account, “your AWS Health Dashboard shows both public events and account-specific events” [1]. When you’re operating in a multi-account environment with AWS Organizations, AWS Health can also emit organizational events, which provide a centralized view across all accounts in your organization.
To simplify management, AWS Organizations allows you to designate a delegated administrator for AWS Health. This admin account collects Health events from all member accounts in the organization, making it easier for security teams to monitor risks centrally [2]. AWS encourages integrating Health events into your monitoring and response pipelines, because learning about potential risks in real time is the first step to containing them.
Integrating AWS Health with EventBridge for Automated Response
AWS Health integrates natively with Amazon EventBridge, allowing you to programmatically respond to events. For our use case, we’ll build an automated incident response pipeline for the AWS_RISK_CREDENTIALS_EXPOSED event.
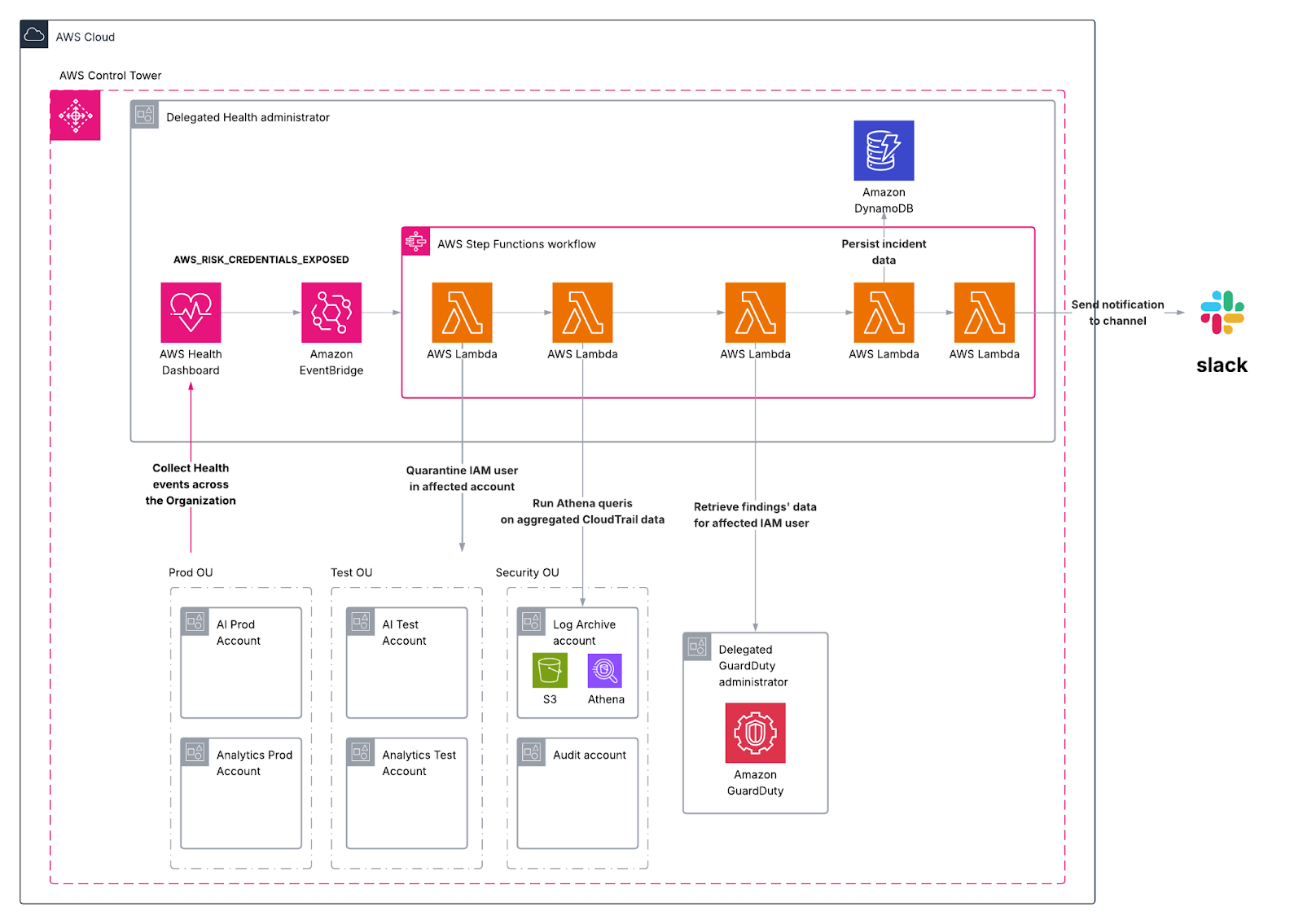
In this architecture, AWS Control Tower governs the organization. Within Control Tower, we are going to enable AWS Health and provision a delegated Health administrator account, which listens for all credential exposure events across the organizations. When such an event occurs, EventBridge rules in the admin account route the event to an AWS Step Functions state machine that orchestrates the response.
The first step in the pipeline is to quarantine the exposed IAM user. An AWS Lambda function is invoked to disable the user’s access by deactivating their access keys, deleting their login profile and detaching all attached IAM policies. Instead of deleting the user immediately, the Lambda function tags them as “Quarantined” and, optionally, places them in a dedicated IAM group with no permissions. This approach preserves the identity for later analysis while ensuring the principal can no longer take actions. Next, the pipeline launches an investigation phase. AWS Control Tower automatically provisions an organization-wide AWS CloudTrail trail across all regions and delivers logs to a central Amazon S3 bucket [3]. A Lambda function could trigger Amazon Athena queries against this centralized trail, filtering by the quarantined IAM user’s activity. This produces a detailed view of the user’s last API calls, including whether they attempted any sensitive actions such as listing or downloading data from Amazon S3.
Let’s assume that Amazon GuardDuty is also enabled in the organization with a delegated administrator account. Then, the pipeline could query it for findings to create correlations about the specific user. GuardDuty continuously monitors AWS account activity and produces findings for IAM-related threats such as anomalous API calls, attempts to escalate privileges by attaching new policies, etcetera. It can also detect suspicious patterns like calls from known malicious IP addresses or unusual login attempts [4]. When GuardDuty is enabled at the organizational level, findings generated in member accounts are automatically forwarded to the delegated admin account, but also remain visible in the originating member account [5]. The pipeline uses the AWS SDK to query GuardDuty and list potential findings on the access key ID or username across all detectors. If related findings are detected, they are retrieved and associated with the incident record to provide additional context for investigation.
After that, the pipeline persists all the collected data into an Amazon DynamoDB table. A fitting schema for this table uses the Health event ARN or a generated incident ID as the partition key. Each item can store fields such as the account ID, IAM username, access key IDs, timestamps for quarantine, links to Athena query results in S3, summaries of GuardDuty findings and a current incident status. This structured persistence ensures analysts can query, enrich and resolve incidents consistently, while maintaining a durable audit trail of the response. For example, the following schema could be used :
Table: credential_incidents
- incidentId (Health event ARN or generated UUID) : string [PK]
- accountId/username/accessKeyIds : string
- status (QUARANTINED, FORENSICS_DONE, CLOSED) : string
- athenaArtifacts (S3 URIs, queryIds) : string
- guarddutySummary (count, maxSeverity, types) : map
- created_timestamp : string
The final step of the state workflow is to notify the relevant teams about this security breach, either through Amazon SNS or by directly sending a message in a Slack channel.
The following diagram displays the proposed architecture in an AWS Control Tower context:
What This Means for You
With this design, organizations implement automated safety measures against exposed IAM user credentials. Instead of relying on untimely manual investigation, the response pipeline ensures that compromised users are immediately quarantined while preserving evidence for later analysis. Security teams receive correlated insights from CloudTrail and GuardDuty without having to manually run ad-hoc queries. DynamoDB serves as a reliable store of every incident record, which supports both operational response and compliance reporting. For security engineers, this approach means faster containment and reduced risk of data loss. For platform teams, it centralizes Health event monitoring in a delegated administrator account, simplifying operations across large AWS Organizations. For data science and machine learning engineering teams, it means they can continue benefiting from the agility and convenience of shared credentials in collaborative environments, but with security measures in place to quarantine compromised users and preserve evidence. This way their workflows are not blocked by complex access permissions’ models, while still allowing the organization to maintain a baseline level of protection against credential leaks - until the company transitions to the recommended model of temporary, role-based access.
What’s Next
By leveraging the AWS Health integration with EventBridge, Step Functions and other AWS services, you can transform credential exposure into a managed and auditable workflow. While this post focused on IAM user key exposure, the same patterns can be extended to other Health events, such as EC2 retirement alerts or SageMaker Notebook instance security notifications. If you’re looking to experiment with this approach in your own environment or create a PoC, start by designating a delegated administrator for AWS Health in your AWS Organization and then build an EventBridge pipeline to respond to the AWS_RISK_CREDENTIALS_EXPOSED events. From there, you can set-up the investigation queries, GuardDuty integration and notification processes to your needs.
If you’d like to understand how this pattern can be integrated into your organization and set-up at a more detailed, technical level, reach out to us and we’ll work with you to design the most effective solution.
Want to see how this approach can strengthen your security posture? Let’s design it around your environment.
From FinTech compliance to ML research pipelines — we’ve seen the challenges and built solutions that keep teams secure without slowing them down.
References
[1] “Concepts for AWS Health”, AWS Docs, https://docs.aws.amazon.com/health/latest/ug/aws-health-concepts-and-terms.html#aws-health-dashboard-term
[2] “Aggregating AWS Health events across accounts”, AWS Docs, https://docs.aws.amazon.com/health/latest/ug/aggregate-events.html
[3] “Logging AWS Control Tower Actions with AWS CloudTrail”, AWS Docs,
https://docs.aws.amazon.com/controltower/latest/userguide/logging-using-cloudtrail.html
[4] “GuardDuty IAM finding types”, AWS Docs,
https://docs.aws.amazon.com/guardduty/latest/ug/guardduty_finding-types-iam.html
[5] “Viewing generated findings in GuardDuty console”, AWS Docs,
https://docs.aws.amazon.com/guardduty/latest/ug/guardduty_working-with-findings.html
Relevant Success Stories
.png)
.png)
Book a meeting
Ready to unlock more value from your cloud? Whether you're exploring a migration, optimizing costs, or building with AI—we're here to help. Book a free consultation with our team and let's find the right solution for your goals.